
 Estos días he estado en la International School and Conference on Network Science (NetSci ’15). Era la primera vez que asistía a esta conferencia y la verdad es que me ha parecido muy interesante. Es un campo todavía nuevo para mi y apenas conozco a nadie, pero bueno, poco a poco.
Estos días he estado en la International School and Conference on Network Science (NetSci ’15). Era la primera vez que asistía a esta conferencia y la verdad es que me ha parecido muy interesante. Es un campo todavía nuevo para mi y apenas conozco a nadie, pero bueno, poco a poco.
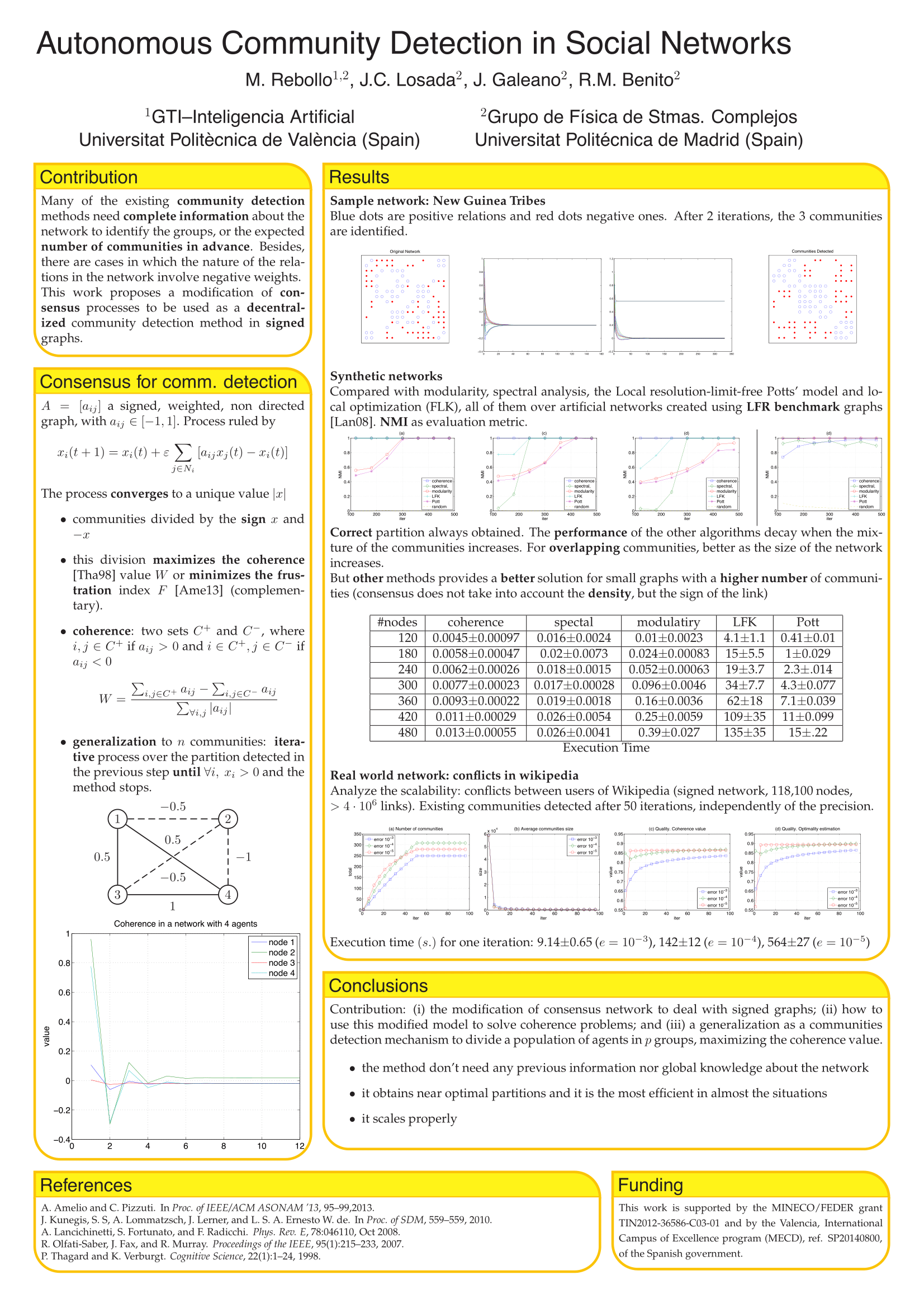
El jueves presenté una de las cosas en las que estoy trabajando: los procesos de consenso en redes para tomar decisiones. Y esta vez, aplicado a la detección de comunidades de forma autónoma. La detección de comunidades es un problema conocido en el campo de las redes. Se trata de, dada una red (por ejemplo, conversaciones en Twitter, contactos en Facebook, pero también colaboraciones en artículos científicos o conexiones entre ciudades), detectar los grupos que existen en ella. Normalmente, hay un grupo cuando un conjunto de nodos de la red está más conectado entre sí que con el resto de la red, es decir, los grupos o las comunidades se detectan atendiendo a la densidad de las conexiones (alta dentro del grupo, baja entre grupos).
El método que he presentado tiene algunas diferencias:
- usa redes con signo: es decir, los enlaces pueden ser positivos o negativos, indicando relaciones de amistad/enemistad, me gusta/no me gusta, etc.
- no necesita saber de antemano cuántas comunidades existen
- trabaja con información local: cada nodo de la red solo conoce su propia información y la de sus vecinos directos. No sabe nada sobre el tamaño de la red, su estructura o ninguna otra característica global.
El proceso comienza asignando un valor aleatorio x a cada nodo. Se ejecuta el proceso de consenso (tratando de acercarse al valor de los vecinos) hasta que converge (no hay diferencias entre una iteración y la anterior). El resultado del proceso de consenso es la división de la red en dos grupos según el signo del valor final: aquellos con x > 0 pertenecen a un grupo y los que tienen x < 0 al otro. Si necesitamos hacer más divisiones, simplemente repetimos el proceso hasta que no haya más divisiones.
Hemos probado con algunos ejemplos conocidos, como la red que modela las relaciones entre tribus de Nueva Guinea y se detectan correctamente las 3 comunidades que existen realmente.
Para comprobar el rendimiento, hemos empleado un benchmark de detección de comunidades y hemos comparado nuestros resultados con otros métodos bien conocidos (ver el póster). El resultado es que el método que proponemos funciona mejor cuanto mayores son las redes. Cuando hay mucha mezcla entre grupos también funciona mejor que el resto. El único caso en el que obtiene peores resultados es para redes pequeñas y cuando hay un número elevado de comunidades. En cuanto al tiempo de ejecución, ahí el método es más eficiente que todos los demás con diferencia, sacando al menos un orden de magnitud (10 veces menos) al siguiente mejor método, y llegando a ser casi 10.000 veces más rápido que otras técnicas habituales (para redes de 500 nodos)
Por último, para comprobar si escala bien a redes grandes, lo hemos aplicado al dataset sobre conflictos en la Wikipedia. Es una red con más de 100.000 nodos y unos 4 millones de enlaces. Nuestro método sigue comportándose bien.
Algo que queda por hacer, es modificarlo para que sea capaz de obtener las comunidades en redes dinámicas, es decir, que la red cambie mientras se construyen las comunidades y que los grupos cambien cuando la red se modifique. Ya tenemos resultados en ese sentido que simplemente hay que adaptar para este caso. Otro tema es, en lugar de construir el grupo atendiendo a un criterio x, tratar de construir las comunidades a partir de varias dimensiones (x1, x2, x3,…) De nuevo, también es algo en lo que estamos trabajando y que posiblemente en unos meses podamos aplicar a este caso también.
Os dejo una copia del póster, por si a alguien le interesa (pincha en la imagen para verlo en grande)
![]()
![]()