

«Hacía frío, casi lo podía sentir atravesando el traje. Pero lo peor era la oscuridad, completa. Desde pequeño siempre le inquietaba. No era miedo, era una sensación extraña, como de estar a un palmo de una pared. De no poder verla pero sentir que estaba ahí. Ni una sola referencia para saber si estaba en un sitio diminuto o inmenso, encerrado en un zulo o de pie en una llanura infinita.
A tientas, desenganchó un estuche del cinturón y lo abrió. Un puñado de esferas zumbaron al activarse perezosas y desplegarse a su alrededor. Cada una de ellas tomó un rumbo y comenzaron a reconocer el terreno y recrear un mapa. En menos de un minuto el sistema de realidad aumentada de su casco le mostró una imagen de su entorno. Apenas una decena de metros, como si el mundo acabara al final de una linterna. Más allá, la nada, dragones, quién sabe. Giró en redondo. Estaba completo; de momento todas las esferas funcionan y se están sincronizando bien.
Las bolas continuaban con su danza, explorando cada vez un poco más, compartiendo la información con sus vecinas para recrear el mundo en 3D, identificando los elementos que ya conocían, marcando los desconocidos. Él era una bola más y le bastaba con tener una o dos cerca para recibir toda la información. Adelantó la pierna izquierda y suspiró aliviado cuando notó el suelo donde se suponía que debía estar. El primer paso siempre era el más difícil«
(fragmento de Éxodo)
Hace un par de semanas estuve en el XXIII Congreso de física estadística (FISES’22) presentando un trabajo sobre aprendizaje federado (federated learning). Es una técnica de aprendizaje automático que permite repartir el conjunto de entrenamiento en varios ordenadores y luego combinar las redes neuronales que ha aprendido cada uno, en lugar de hacerlo todo en una sola máquina.
Aprendizaje federado
Si el conjunto de entrenamiento es muy grande, como los que emplea Google para sus imágenes, o GPT-3 o DALL-E para sus modelos de lenguaje, se tardan semanas o meses en tener la red neuronal entrenada. El aprendizaje federado nos permite reducir mucho estos tiempos. Además, evitamos problemas de privacidad por tener que compartir datos.
Lo que hace este sistema es que cada ordenador entrena su red con los datos que le han tocado (o los que tiene) y envía la red ya entrenada a un servidor central. Este combina todos los modelos, por ejemplo, haciendo la media de los pesos de todas las redes, y devuelve el modelo resultante a cada cliente, que vuelve a pasarle su conjunto de entrenamiento y reajustarlo. Después de unas cuentas iteraciones de entrenamiento / promedio / entrenamiento /promedio / … llegamos a un modelo con una precisión equivalente a la de la red entrenada en un único ordenador, pero con muchas menos iteraciones.
Pero el aprendizaje federado sigue teniendo un problema: que el servidor central es un cuello de botella. Y además hay que incluir el coste de las comunicaciones, que para redes con varios billones de parámetros no es despreciable. Y aquí es donde llega el consenso.
Aprendizaje federado por consenso
Ya he hablado más veces del consenso en este blog. Es mi tema de investigación desde hace unos años. La idea general es poder calcular una magnitud de forma distribuida en una red, usando solo la información de los vecinos más cercanos, sin nadie que lo coordine y sin ningún tipo de información global: cuántos nodos hay o cómo están conectados. En este caso, lo que vamos a hacer en la red es construir ese modelo promedio.

Imagina que tienes una red de sensores y cada uno aprende de sus datos. Cada uno
- entrena una red neuronal con los datos que ha observado
- intercambia con los vecinos el modelo entrenado
- calcula el modelo promedio y se va aproximando a la media de sus vecinos
- con un modelo promediado, reentrena con sus datos (o con los nuevos que haya podido obtener mientras)
Y este proceso se repite varias veces hasta que cada sensor dispone de un modelo bien entrenado. Las ventajas de hacerlo así es que no hace falta ningún servidor que lo coordine, si algún sensor falla, el resto sigue trabajando y no hacen falta grandes infraestructuras (simplemente redes de corto alcance formadas con conexiones entre pares).
¿Qué tipo de red es más eficaz?
El resultado del consenso es independiente de cómo estén conectados los nodos (sensores) entre sí, pero afecta a la eficiencia del proceso. Algunas configuraciones pueden hacer que se tarde más o menos en llegar al consenso, que hagan falta más o menos mensajes. En este trabajo, que era para un congreso de física estadística, nos hemos centrado en estos detalles: ¿hay alguna forma óptima de conectar los sensores entre si? La respuesta final aún no la tenemos: es un proyecto que acabamos de empezar, pero hemos dado los primeros pasos que al menos nos permiten descartar cosas.
El primer paso ha sido probar con seis tipos de redes: tres regulares, con los nodos en posiciones fijas y equidistantes, y tres aleatorias, conectando a los nodos que están dentro de un radio determinado. Los modelos son
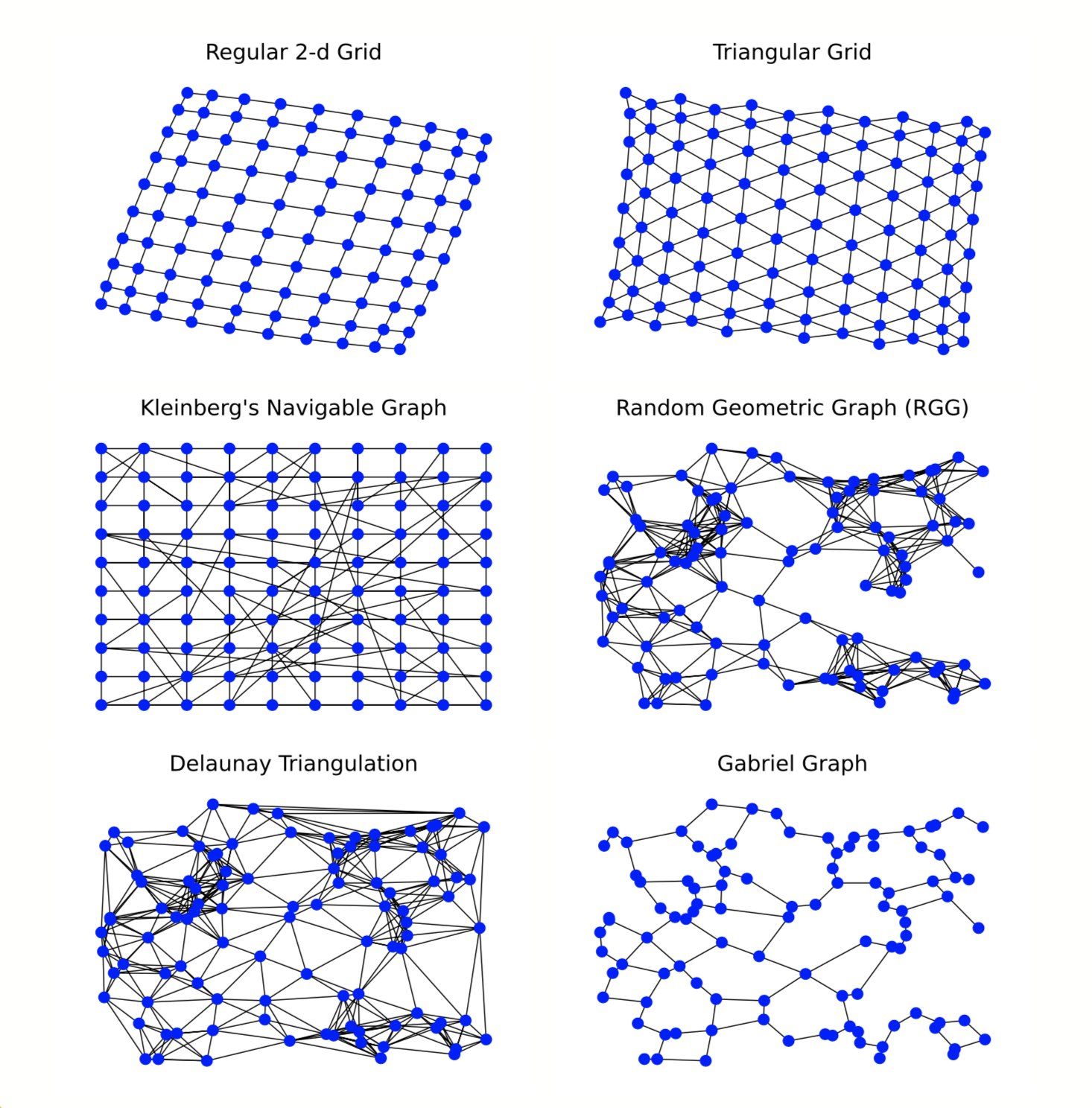
- grid regular 2d, conectando a los 4 vecinos más cercanos
- grid regular triangular
- red de kleinberg: comienza con un grid regular 2d y se añaden enlaces aleatorios, con probabilidad inversamente proporcional a la distancia (cuanto más cerca, más probable es conectarse)
- random geometric graph (RGG): los nodos se distribuyen al azar en el espacio y se conectan todos los que están dentro de un radio r
- triangulación de Delaunay: la dual de los polígonos de Voronoy. Une los vértices que pertenecen a dos polígonos adyacentes
- red de Gabriel: a partir de la anterior, solo conserva los enlaces mínimos más cercanos
En el artículo hay un análisis más detallado, pero la conclusión principal es que las redes regulares, aunque son más tolerantes a fallos y eficintes en cuanto a los procesos de difusión en general, no lo son tanto en el rendimiento del consenso, especialmente cuando el tamaño de la red aumenta.
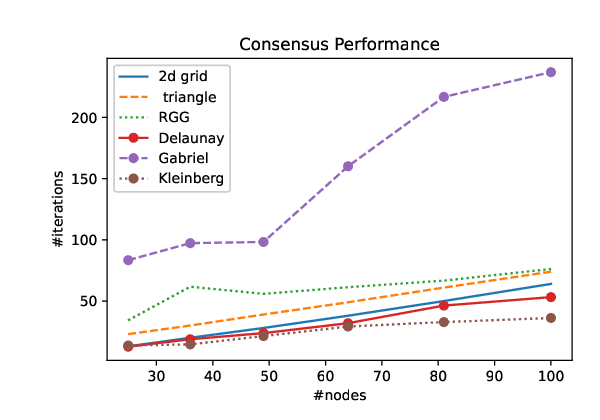
Necesitamos reducir tanto como sea posible el número total de mensajes. Por eso, las RGG son las topologías más prometedoras, especialmente cuando aumenta el tamaño de la red. Tienen un rendimiento para hacer aprendizaje federado mediante consenso y una robustez adecuadas.
Precisión del consenso federado
La solución a la que llega el modelo centralizado con el modelo federado (ya sea por consenso o usando un servidor) no es la misma, pero sí que lo es su calidad. Sin embargo, el consenso federado consigue una mejor precisión con menos iteraciones.
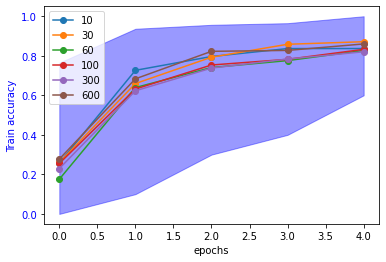
Para las pruebas en este trabajo hemos usado MNIST: un ejemplo de reconocimiento de cifras manuscritas. Está formada por 60.000 ejemplos para entrenar la red y otros 10.000 para testearla. Es relativamente sencillo obtener buenos resultados: ya con la primera iteración se obtiene una precisión del 60% Pero este ejemplo lo hemos usado solo para validar que el modelo funciona y que el tipo de red selecionado. Hemos probado desde redes pequeñas, con 10 nodos (cada uno generando un modelo a partir de 6.000 muestras) hasta redes de 600 nodos (que generan modelos con 100 muestras). En todos los casos se obtienen resultados similares. Las líneas son la precisión media obtenida con 10 repeticiones y el área sombreada representa la diferencia entre la mejor y la peor precisión de todos los experimentos.
M. Rebollo, C. Carrascosa, J.A. Rincon (2022) Federated Learning mediante consenso. En XXIII Congreso de Física Estadística (Fises’22), p 191. Zaragoza, 2022