
Con este primer tema empezamos las clases del master IARFID, hablando de qué son los agentes en general y de las características particulares de los agentes de la información. A continuación tienes las transparencias de este tema.
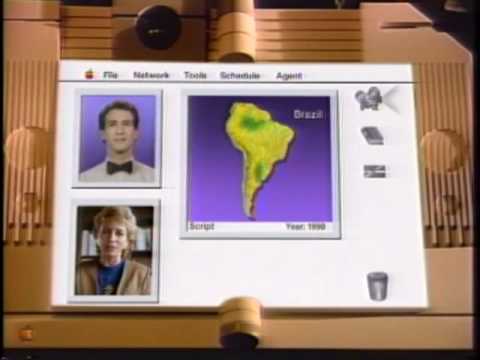
Como otros años, para hablar de todo esto sigo utilizando el vídeo Knowledge Navigator, creado por Apple en 1987 (dentro de poco hará 25 años). Todavía hoy sigue habiendo algunas cosas que son irrealizables, especialmente en todo lo que se refiere al procesamiento del lenguaje natural (incluyendo el no verbal). Sin embargo, en cuanto al hardware no van tan desencaminados; incluso está algo por debajo. El dispositivo en sí no es tan diferente de un iPad.
Finalmente, como actividad para realizar hasta la siguiente sesión, tenéis que leer dos artículos: uno de TIm Berners-Lee hablando sobre la web semántica y los agentes y un editorial de la revista IEEE Intelligent Systems
- Tim Berners-Lee, James Hendler and Ora Lassila B.: The Semantic Web. A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities.- Scientific American.com, may 17th, 2001. http://www.med.nyu.edu/research/pdf/mainim01-1484312.pdf
- Where are all the Intelligent Agents?
James Hendler: Where Are All the Intelligent Agents?.- IEEE Intelligent Systems, vol. 22, no. 3, pp. 2-3, May/June 2007, doi:10.1109/MIS.2007.62. Disponible en http://www.computer.org/portal/web/csdl/doi/10.1109/MIS.2007.62
El trabajo a realizar consiste en leerlos y dejar como respuesta a esta anotación vuestra opinión al respecto. No se trata de resumirlo, sino de que os posicionéis respecto a estas opiniones y deis vuestros propios argumentos. No os olvidéis indicar vuestro nombre, ya que esta es una actividad que puntuará para la nota final.
«Where are all the agents?» as stated by James Hendler clearly states current state of affairs on semantic web and agents. The promise as described to be near future by sir Tim Berners-Lee in the year 2001 as of yet lives to be unfulfilled. How did this happen? The basic building block artifacts (XML, RDF and ontologies) have been among us for quite some time already, but massive market evolution has not taken place.
I believe that the delayed adoption of the semantic web (and it’s agents for that matter) is not a technological issue, but rather a cultural one. In order for companies to start using the SW technologies they need tools (IDE’s for web development that actively support semantic annotation for instance), and for these tools to be created a concrete killer app needs to be devised otherwise expected benefit is simply not high enough. Conceiving this killer app requires a major paradigm shift away from data centered thinking towards semantically driven approaches.
It is only through this change that we can start thinking in the adequate direction, and eventually create a web of collaboration, information, shared ideas and concepts; or in short, the semantic web.
Me opinión se decanta más por el artículo de James Hendler.
Pienso que la idea que propone Tim Berners-Lee es muy buena y sería ideal disponer de ella en la práctica. Se pensaba que para los años actuales ya sabríamos procesar textos y voz perfectamente pero la tecnología aún no lo ha alcanzado ya que presenta numerosas dificultades. Se han creado ontologías OWL que pocas webs las siguen, si todos siguieran los estándares y las propuestas para la web semántica funcionaría muy bien pero aún no se ha conseguido. También estoy con Hendler en que aún no se ha visto un acercamiento inteligente en la web para pensar en agentes inteligentes.
Mercedes García
Me posiciono mas a favor del articulo de James, aunque admito que 10 años para todo lo que se prometió es muy poco.
Quizas Tim, James y Ora se crecieron por «la fiebre de los agentes» de aquella época y prometieron/auguraron algo que parece lejano aún hoy en dia.
Tal vez ha sido la avaricia de las compañias lo que ha impedido que muchos estandares se afianzen pero, lo que está claro es que a nivel de investigación el procesado semántico aún debe seguir mejorando si queremos acabar dandole la razón a la gente que defiendió la web semántica.
El artículo «The Semantic Web» de Tim Berners-Lee y otros, en mi opinión, está muy bien enfocado teniendo en cuenta que se describe de manera simple pero abarcadora todos los puntos de mira a los que en su momento había que prestar atención para lograr tener agentes inteligentes que mediante la cooperación y el acceso a una información adecuadamente estructurada se lograra solucionar prácticamente cualquier tipo de problema. Considero que son planteamientos ambiciosos sobre todo por la proximidad con la que se esperaba tener estos resultados, sin embargo necesarios para sentar bases hacia el desarrollo y logro de estos objetivos.
En “Where are all Intelligent Agents?” James Hendler en cambio nos pone sobre la mesa un problema quizás se menospreció un poco en el primer artículo, y es que tener una aplicación práctica en la que existan agentes autónomos que cooperen y ofrezcan un resultado fiable y rápido es complicado desde el punto de vista tecnológico y también por el cambio de mentalidad que implica, además de que requiere una infraestructura consolidada y estable. Opino que la interrogante que nos plantea el autor obtendría respuestas más favorables si se intenta llevar adelante esta tecnología a un ámbito de aplicación de mucha menor escala con miras a irse ampliando progresivamente.
Teniendo en cuenta la situación visible en internet sobre los agentes y su adopción considero más adecuada la postura de James Hendler en su artículo «Where are all the the intelligent agents?». Ciertamente desde finales de los 90 ha habido una explosión en el desarrollo de las tecnologías base para la proliferación de los agentes ( Servicios Web, OWL, XML, RDF, Directorios,… ) pero sin embargo los agentes no están ahí.
A mi entender esto se debe primordialmente a:
1. Los actuales estándares de desarrollo de la industria – Actualmente no hay ninguna obligación o reglamentación para que una página web ofrezca estos servicios o siga un estándar.
2. Las facilidades y herramientas de las actuales herramientas de desarrollo – Los actuales procesos de desarrollo y las herramientas utilizadas van encarados hacia la presentación de datos para el humano. Incluso las herramientas para la generación de servicios web no contemplan el seguimiento (o generación de la estructura necesaria) para cumplir con el estándares necesarios de la web semántica.
3. El actual modelo económico de internet – Principalmente se basa en: pago por acceso a una información, venta online de un producto físico, publicidad. De las tres formas anteriores claramente las que más han proliferado es la de acceso a información y contenido libre pero con remuneración económica debido a publicidad. Teniendo esto en mente no parece ser que los creadores de los contenidos quieran dar un acceso fácil de dicha información a sistemas (agentes) para que consuman la información de una forma no deseada por el autor/distribuidor. Siendo este tercer punto la causa principal de los dos puntos anteriores.
Mi opinión es que hasta que no exista un modelo económico aceptable por los autores/distribuidores ( o un cambio de mentalidad más profundo pero no muy factible) la información no estará disponible de verdad para consumir de forma automática y por lo tanto los agentes en verdad no pueden proliferar.
Al margen de lo comentado anteriormente creo que lo expuesto en el artículo de de Tim Berners-Lee, James Hendler y Ora Lassila «The Semantic Web» como una muy buena hoja de ruta y descripción de las posibilidades de la proliferación de los agentes simplemente que como cualquier concepto o sistema deja de lado el factor humano ( en este caso más económico).
El conjunto de ideas que plantea «The semantic web» parecen muy buenas, pero para que estas ideas sean soportables el mundo se tendría que adaptar a los agentes.
Si miramos en la actualidad muchos sistemas de información, como pueden ser Webs, no se adaptan a un estándar y para los sistemas que lo hacen nos tendríamos que preguntar si los estándares que existen se adaptan a los agentes.
Es por ello que estoy de acuerdo con el articulo «Where Are All the Intelligent Agents?». Ya que es muy fácil pensar que todos los sistemas de información se van a adaptar a los sistemas de agentes que se pretendan crear. Pero esto es realmente difícil porque estos sistemas de información tendrían que ser creados explícitamente para ser estudiados por agentes, ya que ahora mismo se realizan para que sean estudiados por personas.
Para que empiecen a existir estos sitios debe haber algún interés mas, y como casi siempre este suele ser el económico. Un claro ejemplo podría ser esta aplicación creada con la colaboración de Apple.
http://siri.com/about/
Donde podemos ver varios sitios webs que ofrecen servicios para que la aplicación funcione. Es por ello que no es tan difícil conseguir lo que presenta el primer artículo sino que solo hacen falta servicios de información que se adapten a los agentes.
Pero está claro para que el mundo se adapte a una aplicación debe existir un interés más grande que el puro interés del avance tecnológico.
Analizando ambos artículos y teniendo en cuenta la situación actual en la que nos encontramos, me considero más partidario del artículo «Where Are All the Intelligents Agents?» de James Hendler. El autor comenta, basándose en su propia experiencia de trabajo, cómo la falta de heterogeneidad complica la aplicación real de estos sistemas. Esto es algo que podemos observar fácilmente hoy en día. La mayoría de artículos sobre el tema son demasiado teóricos y por lo tanto no tienen en cuenta las limitaciones que existen en realidad.
Por otro lado, todo lo que se expone en el otro artículo titulado «The Semantic Web» de Tim Berners-Lee, James Hendler y Ora Lassila expresa claramente la meta que se desea alcanzar, y que aún resulta algo lejana. Seguramente en su momento no tuvieron en cuenta todos los problemas que continuarían existiendo adía de hoy. Aún así resulta muy interesante ya que muestra su gran utilidad y es un claro referente en el tema.
Como conclusión, nada de esto será posible mientras no se impongan obligaciones en la estandarización y en los servicios que debe ofrecer una web, ya que sin ello será imposible realizar un uso inteligente de toda la información disponible. Para ello no basta con presentar más artículos de investigación, si no hacer ver su utilidad y hacer que las empresas se interesen por ello.
Me posiciono en el artículo de James Hendler, «Where are all the intelligents agents?». Es cierto que la tecnología base para el desarrollo de agentes y de la web semántica ya existe, tal como apuntaban ambos artículos, pero implantar la web semántica a gran escala tiene varios puntos en contra fundamentales:
-Se tienen que cambiar TODAS las webs para etiquetar el contenido –> Coste económico
-Se tiene que cambiar la forma de trabajar y las herramientas para desarrollo de webs –>tiempo y dinero
-Aparición de los agentes y el fin de la navegación por internet por las personas, por lo que no sería rentable la publicidad en internet –> menos ingresos
El futuro que se nos muestra en «The Semantic Web» es, tecnológicamente, el ideal ya que gracias a los agentes ahorraríamos tiempo en nuestras gestiones evitándonos ciertas decisiones de bajo nivel (horarios, citas, ubicación de los sitios, reservas, etc.). El problema es que el Mundo Internet ya existe y los cambios siempre son complicados, además de que comportan elevados costes adicionales.
El desarrollo de los agentes inteligentes tomaría un nuevo impulso cuando los agentes puedan interpretar textos de forma automática(sin necesidad de etiquetado) ya que de esta forma no se necesitaría de la colaboración del resto de la industria (se eliminarían los costes de la adaptación) y el progreso en la implantación de los agentes dependería solamente de la ventaja competitiva respecto a las herramientas tradicionales.
Con los conocimientos que tengo sobre los agentes y la web semántica, después de leer ambos artículos me decanto por el artículo de «Where are all the intelligents agents?» de James Hendler. Ya que nos da una idea desde cuando se lleva hablando del concepto de «agentes» en la web, y nos comenta alguno de los lenguajes, como DXML,DAML+OIL, … que actualmente se utilizan para la creación de servicios web y esos servicios web pueden actuar como «agentes» que actúen con cierto criterio para consultar bases de datos, otras web, … Por el contrario el otro artículo propone muchas conceptos e ideas que idealmente son muy buenas, y que para mi entender serían costosas en tiempo y dinero. Además hay características que hay que mejorar dentro del campo de los «agentes» para que funcionen de forma autónoma y puedan comprender el sentido de los textos, …. dentro de la web.
Para empezar, el texto de James Hendler fue escrito en 2007, es decir, hace una eternidad. De todos modos, Hendler no está preocupado por dónde están los agentes, no es una pregunta que se haga a sí mismo. Simplemente está mostrando una de tantas predicciones tecnológicas para el futuro que al final acaban siendo erróneas.
Pero, ¿qué es un agente? Tomando una definición superficial de agente como una pieza de software con métodos de entrada y de salida, con un objetivo, que interacciona con el ambiente y bla bla bla, yo veo agentes por todas partes.
O al menos, si no se pueden llamar agentes como tal, veo, en cientos de webs, comportamientos como los que predecía Tim Berners-Lee.
Hay muchas páginas donde pones un par de fechas, un sitio al que ir y poco más y en 10 segundos te han buscado vuelo de ida, vuelo de vuelta, coches de alquiler, precios asequibles de hostels si eres joven, descuentos si ya has utilizado ese servicio antes y te recomiendan varios tours para hacer allí.
Hay aplicaciones en cualquier smartphone que pasando un código de barras por delante de la camara del móvil, te muestra los precios de ese artículo en miles de tiendas para que puedas comparar.
En la mayoría de las tiendas on-line, las ofertas que te ofrecen ya son personalizadas, dependiendo lo que hayas buscado anteriormente, tu edad, tus criterios de búsqueda…
No sé como se implementa todo esto, pero lo cierto es que los comportamientos que describe Berners-Lee YA son una realidad en muchos aspectos. Y si no se realizan mediante lo que Hendler estrictamente considera agentes, quizá es que hay otras técnicas más sencillas y/o más económicas.
Personalmente creo que los dos textos tienen su razón. La opinión de Tim Berners-Lee y compañia sigue en la linea de lo que se puede llegar a desarrollar sin propuestas concretas. Plantean los dos extremos de servir a pequeños grupos ó servir a la gran masa. Creo que servir a la gran masa es inviable si no se es capaz de funcionar con pequeños grupos primero. Por otra parte, la opinión de James Hendler es más realista y aporta una experiencia personal muy importante, pero tambien parece que se intenta comer todo el pastel de golpe intentando encontrar una solución global de una forma muy directa. Yo creo que la información de la WEB es demasiado amplia y extensa como para intentar hacer
estandares. Además me atreveria a decir que hay casi tantas WEBs como desarrolladores de estas por lo que formar a todas estas personas e intentar abarcar todos campos posibles es hoy totalmente inviable.
Creo que el maravilloso mundo que nos puede ofrecer la Web Semantica deberia de empezar de forma que el que desarrolle una WEB con esta tecnología deberia crear tambien los agentes para acceder a esta. Los usuarios que les interese este servicio pueden adquirir (comprado ó regalado) el agente necesario. Esto nos puede llevar a una situación donde tengas una buena colección de agentes pero con el tiempo y la experiencia se podra dar el segundo paso de estandarizar los agentes.
Leyendo la «disputa» entre estos dos artículos viene a mi cabeza la conocida saga de Robert Zemeckis «Regreso al Futuro» en la que un joven Marty McFly llegaba a un mundo lleno de coches volando por las ciudades y restaurantes dirigidos por máquinas, en un totalmente fantástico año 2015 del cual no estamos nada lejos y del que hoy en día, a falta de 4 años, nadie diría que existirán cosas ni parecidas. Sin embargo disponemos de unos trenes que son capaces de circular sin tocar las vías, no vuelan, pero casi.
Pues con los agentes de información pasa lo mismo, es normal que se pensara que en los años 2k se fuera a tener de todo (incluso tu propio coche que vuela, o tu agente inteligente que vuela, puestos a pedir), pero para eso alguien lo tiene que hacer y alguien lo tiene que necesitar, y en un mundo en el que la mayoría de desarrolladores web se preocupan más por que su página se vea superbien en Internet Explorer que por que pasen con satisfacción los validadores W3C no cabe sitio para que además se coman la cabeza añadiendo más etiquetas para la semántica cuando «eso en Intenet Explorer no se va a apreciar».
Y por supuesto está el tema del poderoso caballero Don Dinero, «algo puede darnos beneficio a largo plazo, además es un avance para la ciencia…a ver, para el carro, ¿eso me va a dar beneficio rápido e inmediato?, ¿no? pues a otra cosa mariposa». Hasta que no haya una demanda importante de usuarios no se dará un soporte mas o menos global a este tipo de tecnología, que por supuesto un día existirá, el día que los desarrolladores quieran gastar tiempo y dinero en algo que a simple vista no va a aparecer en sus páginas y pasará desapercibido para los humanos, pero todo lo contrario para los agentes y quienes los usen, quienes verán un aumento en usabilidad, tiempo de respuesta y sobre todo en comodidad.
En mi opinión , yo creo que los agentes ya están presentes de manera bastante extensa en varias páginas webs, y si no son agentes como los que idealmente definidos en el artículo «THE SEMANTIC WEB» por Tim Berners-Lee ,serán páginas diseñanda para que basándose en el historial de tus visitas o últimas elecciones ya eligen de una manera más o menos acertada el contenido proporcionado, ya sean páginas de e-commerce , como páginas de busqueda (viajes, coches , etc).
Por otra parte creo que en el momento en el que James Hendler y como cita en su artículo «Where are all the intelligent Agents» , empezó a trabajar en DARPA , se centraron más en desarrollar lenguajes y plataformas para Webs que soportan la tecnología de agentes, olvidandose al mismo tiempo que seguían desarrollandose páginas webs por millones, y que al final se encontrarían con el problema de que no hay ningun estandar que seguir por los desarrolladores, y si aun fuera el caso , costaría demasiado dinero y tiempo , volver a diseñar todas las páginas existentes con el nuevo.
Como conclusión , creo que los 2 artículos aportan diferentes puntos de vista, en el artículo de «THE SEMANTIC WEB» por Tim Berners-Lee se define como sería de manera ideal una web semantica y lo tomaría más como una hoja de ruta , obviando claramente los problemas que podrían surgir en el momento de aplicarla.
Por otro lado el artículo de James Hendler «Where are all the intelligent Agents», me parece mucho más critico y realista, ya que después de ser un pionero en el tema de los Agentes Inteligentes, acaba preguntándose si realmente esta tecnología se llegará a estandarizar para todas las páginas web.
Los dos artículos son interesantes para los que desconocíamos que es la web semántica y que objetivos persigue, así como saber que tecnologías usa para su desarrollo.
Así como la WWW utilizo la idea de los hiperlink, que ya existía antes que la WWW aparezca (todavía recuerdo el HiperCard de Apple, el primer software “multimedia” que usaba hiperlinks, que apareció cuando Windows no existía, muchos de mis compañeros de asignatura todavía no nacían), La web semántica utiliza la idea de la representación del conocimiento mediante reglas, claro, adaptada para sus fines.
Estoy de acuerdo que situaciones de uso de la web semántica como lo muestra el ejemplo del articulo o como vimos en el video en clase llegaran a ser realidad, pero tardara unos años.
Como sucedió con internet, primero se utilizara en círculos académicos ,luego en las empresas y luego se masificara, y el uso se hará transparente para el usuario, aunque siempre habrá grupos que por falta de conocimiento estarán relegados en el uso de las bondades que proporcionara la web semántica.
La Web semántica también muestra la utilidad de los agentes y aclara muchas cosas sobre estos que a pesar de haberlos visto en otras asignaturas aun había dudas que quedaban en limbo, ahora se entiende mejor la importancia de los agentes y términos como autonomía, negociación, confianza, ontología.
Flabio gutierrez
El inicio del artículo “The Semantic Web” describe una situación de utopía tecnológica que no se aleja mucho de otras ideas surgidas en otros ámbitos de la IA que han visto como los resultados esperados hace años no se acercan a los obtenidos actualmente.
El modelo de web semántica esperado y deseado por James Hendler sería totalmente viable si dispusiésemos de una inteligencia artificial tal cual fue imaginada años atrás, la cual fuera capaz de reproducir las habilidades cognitivas del ser humano y obtener esa información sobre una web tal cual la tenemos ahora sin necesidad de una estructuración especial. Dado que estamos desviados de ese objetivo, y al menos no dispondremos de ello en un futuro próximo es necesario plantearse las otras opciones basadas en la estructuración y estandarización de las tecnologías web.
Este enfoque personalmente creo que se enfrenta a muchos obstáculos y por tanto está alejado de convertirse en una realidad. Además de ser necesario una nueva mentalización de lo que representa la web y del modelo de negocio existente en la misma, los usuarios que crean los diferentes contenidos web no piensan en servir a los agentes para extraer la información de sus sitios. La estructuración de las tecnologías web hasta el punto en el que los agentes pudieran extraer la información de la forma que se desea sería peligroso para la integridad de la web. Pese a que la utilidad buscada es la de facilitar la vida al usuario en todos los aspectos comentados en el artículo, el control tan restrictivo de los contenidos a su vez facilitaría la censura y el control de los mismos.
No quiero decir que el concepto y la idea de la web semántica sea un imposible, sino que en mi opinión la estandarización de las tecnologías web no es el mejor camino a seguir, y quizá sería mas productivo buscar el modo de procesar y razonar sobre la información existente que imponer un control sobre algo tan complejo como es la web e Internet.
El concepto de web semantica se hace cada vez más necesario ya que existe gran cantidad de información solo accesible por los humanos y de forma muy limitada y reducida por las computadoras.
Pero me pregunto, porque se necesita que la información sea accesible por un ordenador. Principalmente para que los resultados obtenidos a partir de búsquedas o servicios nos puedan ofrecer a mi parecer mejores resultados y de mayor calidad, independientes del sistema y tratados desde diferentes interfaces de usuario según las necesidades.
Así pues el concepto descrito de Web Semantica por Tim Berners-Lee es útil y de necesidad en un futuro próximo si se desea continuar avanzando.
En la actualidad la definición de Web Semantica está clara, así como su forma de trabajo. El problema radica en la puesta en práctica y es aquí donde el articulo de James Hendler pone de manifiesto, ¿Donde estan los Agentes Inteligentes?.
A mi parecer en la actualidad hay un error común, y es que la gente no ve mas allá de la WEB que una simple página HTML comercial, sin estructuración de la información, y dirigida por diseñadores para un «Que bonito» sin importar la información en ella incluida y los servicios que puedan ofrecer.
A su vez la mayoria de clientes no quieren un producto si no ve un objetivo claro, de ahi que yo no me preguntaría ¿Donde están los Agentes inteligentes? sino ¿donde están las interfaces para estos Agentes Inteligentes?
Hemos visto el video de apple en el que se ve el «knowledge navigator», y que es un claro ejemplo de Interfaz para estos agentes, pero claro, parece que se ha quedado en una utopia, pero es entonces donde posiblementes nosotros tenemos que poner nuestro trabajo, y crear dichas interfaces para los agentes.
«Knowledge Navigator» en la actualidad ya no es una utopia, y un claro ejemplo de Web Semantica con Agentes Inteligentes y una interfaz de usuario es Watson de IBM, que demostró en un concurso norteamericano llamado Jeopardy que era capaz de entender frases del presentador con doble sentido, y buscar la respuesta correcta en la Web ofreciendo la respuesta al presentador. Como no, gano a sus dos oponentes. http://www-03.ibm.com/press/us/en/presskit/27297.wss