

 Las redes sociales se están convirtiendo en una herramienta válida para medir el pulso de las ciudades. En este caso, para poner en práctica los resultados de nuestra investigación en el GTI-IA, hemos elaborado una herramienta que permite mostrar la actividad en la zona de influencia de cada una de las más de 300 fallas que se han plantado en Valencia en el 2015 desde buscafallas.com.
Las redes sociales se están convirtiendo en una herramienta válida para medir el pulso de las ciudades. En este caso, para poner en práctica los resultados de nuestra investigación en el GTI-IA, hemos elaborado una herramienta que permite mostrar la actividad en la zona de influencia de cada una de las más de 300 fallas que se han plantado en Valencia en el 2015 desde buscafallas.com.
Los datos que usa son los tuits y las fotos geoetiquetadas que se publican en la ciudad. El problema es que apenas el 1% de los usuarios de las redes sociales activan esta característica, especialmente por cuestiones de privacidad (yo mismo no suelo tenerlo activo). El acceso a la información se realiza mediante el API público para los desarrolladores de Twitter y los desarrolladores de Instagram, junto con los datos públicos que el Ayuntamiento de Valencia proporciona a través de su iniciativa Valencia datos abiertos.
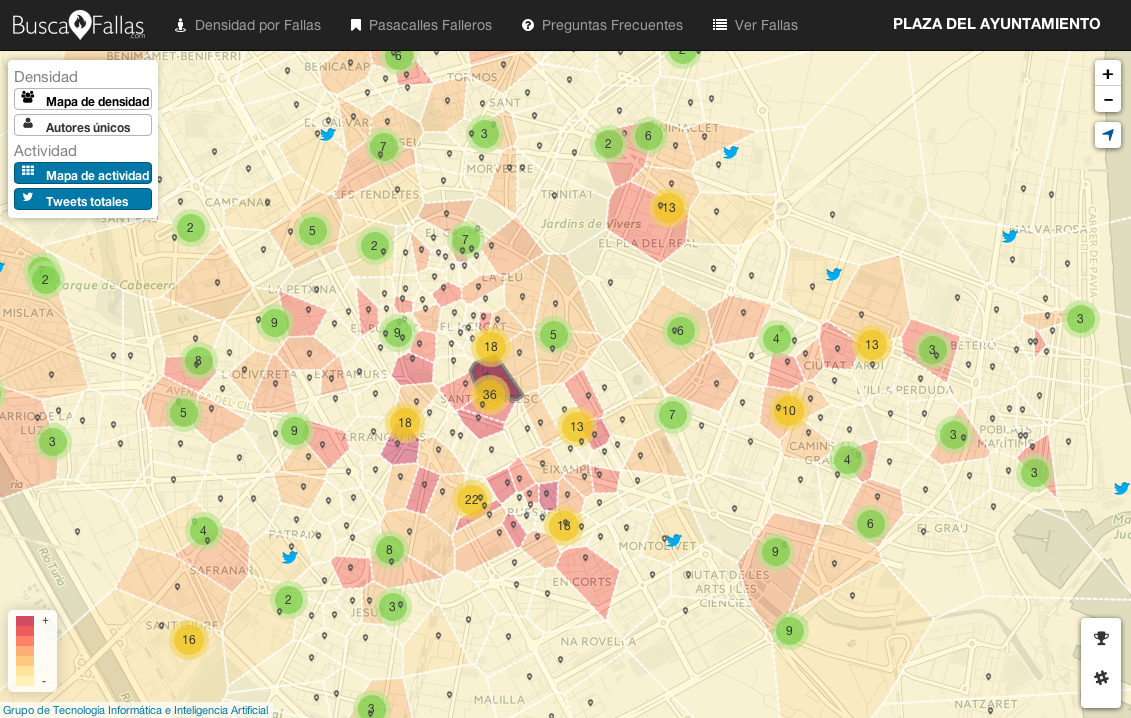
Una vez que conocemos las coordenadas de cada falla, podemos calcular su área de influencia. De m omento, no estamos teniendo en cuenta la sección a la que pertenece la falla y las consideramos iguales a la hora de calcular este área. Una vez calculada, podemos determinar cuántos usuarios activos hay en la zona de influencia de la falla. El mapa se colorea atendiendo a la densidad y marca la cantidad de mensajes de cada zona. Se permiten dos formas de interpretar los datos: por número de usuarios o por actividad total. Si usamos los autores únicos, es decir, considerando solo un tuit/foto por usuario, puede estimarse cuánta gente hay cerca de la falla. Si tenemos en cuenta la actividad general, se puede determinar en qué parte de la ciudad está ocurriendo una actividad relevante (por ejemplo, la mascletà en la Plaza del Ayuntamiento). El usuario puede elegir qué información ver con los botones de la parte superior, a la izquierda. Además, pinchando sobre la falla, pueden verse las etiquetas que la gente está usando en la zona de influencia de la falla, para que sepas de qué se está hablando alrededor de cada una de ellas. Los botones de la parte inferior muestran un ranking de las fallas que están teniendo en este momento más actividad (las últimas 2 horas) y las etiquetas más utilizadas en general en toda la ciudad.
omento, no estamos teniendo en cuenta la sección a la que pertenece la falla y las consideramos iguales a la hora de calcular este área. Una vez calculada, podemos determinar cuántos usuarios activos hay en la zona de influencia de la falla. El mapa se colorea atendiendo a la densidad y marca la cantidad de mensajes de cada zona. Se permiten dos formas de interpretar los datos: por número de usuarios o por actividad total. Si usamos los autores únicos, es decir, considerando solo un tuit/foto por usuario, puede estimarse cuánta gente hay cerca de la falla. Si tenemos en cuenta la actividad general, se puede determinar en qué parte de la ciudad está ocurriendo una actividad relevante (por ejemplo, la mascletà en la Plaza del Ayuntamiento). El usuario puede elegir qué información ver con los botones de la parte superior, a la izquierda. Además, pinchando sobre la falla, pueden verse las etiquetas que la gente está usando en la zona de influencia de la falla, para que sepas de qué se está hablando alrededor de cada una de ellas. Los botones de la parte inferior muestran un ranking de las fallas que están teniendo en este momento más actividad (las últimas 2 horas) y las etiquetas más utilizadas en general en toda la ciudad.
 La web tiene una segunda utilidad: los pasacalles falleros. Hemos creado una aplicación (gratuita, buscafallas está disponible en Google Play) con el que las fallas pueden dar a conocer su posición en tiempo real. Esta información se envía a Buscafallas y desde la web de buscafallas cualquier persona puede ver el recorrido que están haciendo. Puedes usarla para pasacalles, la Ofrenda, la despertà, cabalgatas… Para activarla, necesitas el nombre de usuario y la contraseña de tu falla. Si no la tienes, puedes contactar con nosotros enviando un correo electrónico a gtiia@dsic.upv.es Ten en cuenta que la precisión del GPS puede no ser buena en calles estrechas y no funciona en el interior de los edificios.
La web tiene una segunda utilidad: los pasacalles falleros. Hemos creado una aplicación (gratuita, buscafallas está disponible en Google Play) con el que las fallas pueden dar a conocer su posición en tiempo real. Esta información se envía a Buscafallas y desde la web de buscafallas cualquier persona puede ver el recorrido que están haciendo. Puedes usarla para pasacalles, la Ofrenda, la despertà, cabalgatas… Para activarla, necesitas el nombre de usuario y la contraseña de tu falla. Si no la tienes, puedes contactar con nosotros enviando un correo electrónico a gtiia@dsic.upv.es Ten en cuenta que la precisión del GPS puede no ser buena en calles estrechas y no funciona en el interior de los edificios.
Cuando acaben las Fallas, completaremos la información cuando estudiemos los datos con técnicas de análisis de redes sociales. Quien sabe, a lo mejor somos capaces de predecir qué falla va a ganar el primer premio, como ocurrió con la predicción de Ben Zauzmer sobre los Óscar 2015 ;-)
Algunos detalles técnicos: toda la información que recopilamos, está almacenada en una base de datos creada con MongoDB y para la visualización de los mapas estamos usando Leaflet. La primera opción fue intentarlo con CartoDB, pero tuvimos muchos problemas para configurarlo en nuestro propio servidor, así que al final lo descartamos.
El mérito de todo esto es de Javier Palanca y Elena del Val, que han sido los que han hecho que este proyecto pase del papel a una aplicación real.

