
¿Cómo de seguras son nuestras ciudades en relación al covid-19? ¿Podemos movernos sin peligro a contagiarnos? Si se produce un brote ¿qué partes de la ciudad se ven más afectadas? Los procesos de consenso pueden ayudarnos a elaborar mapas de riesgo del sitio en el que vivimos. Esto es lo que hubiera ocurrido durante el piloto de La Gomera.
En otra ocasión ya comenté un proyecto en el que estamos trabajando sobre usar de procesos de consenso para construir mapas de riesgo, de forma colaborativa y compartiendo información solo con contactos de confianza. Durante estos meses he recogido datos y ya podemos simular su funcionamiento de forma más precisa en cualquier zona. Aprovechando el análisis del piloto de Radar COVID en La Gomera, voy a usar esos mismos datos para hacer una demostración del funcionamiento del algoritmo de consenso y de los resultados que se podrían obtener con una aplicación que lo implemente. El resultado: un mapa que indica el riesgo de infección en cada una de las zonas censales en las que está dividida la isla de La Gomera.
Una aplicación con esta funcionalidad sería un buen complemento para las aplicaciones de rastreo de contactos, como el Radar COVID. Dichas aplicaciones nos indican si en algún momento hemos estado en contacto con alguien infectado. La construcción de mapas de riesgo evitaría movernos a zonas conflictivas. O al menos, si no podemos evitarlo, lo tendríamos presente para tomar las medidas adecuadas y reducir el riesgo.
La administración también lo podría utilizar para prever la evolución de los contagios y tomar medidas preventivas. Por ejemplo, se podrían decretar confinamientos en zonas más pequeñas, antes de que la situación se descontrole, asegurando que dentro de las zonas se dispone de acceso a los servicios esenciales. O se podrian establecer planes para hacer pruebas PCR más localizadas.
¿Cómo funciona el consenso?
De forma sencilla, cada persona tiene un valor para un dato, por ejemplo, la edad. Y queremos calcular la edad media del grupo. Pero no se conocen todos, si no que cada persona solo conoce a unas pocas, como en una red social. El proceso de consenso consiste en lo siguiente:
- cada persona pasa su edad a sus contactos
- con todas las edades recibidas, cada persona hace el siguiente cálculo: a su edad le añade la suma de todas las diferencias entre su edad y la de sus contactos, dividido por el mayor numero de contactos de la red. Esto es \(x_i(t) + \frac{\sum_{j}[x_j(t) -x_i(t)]}{\max_i di}\)
- se actualiza la edad con el resultado de la operación anterior
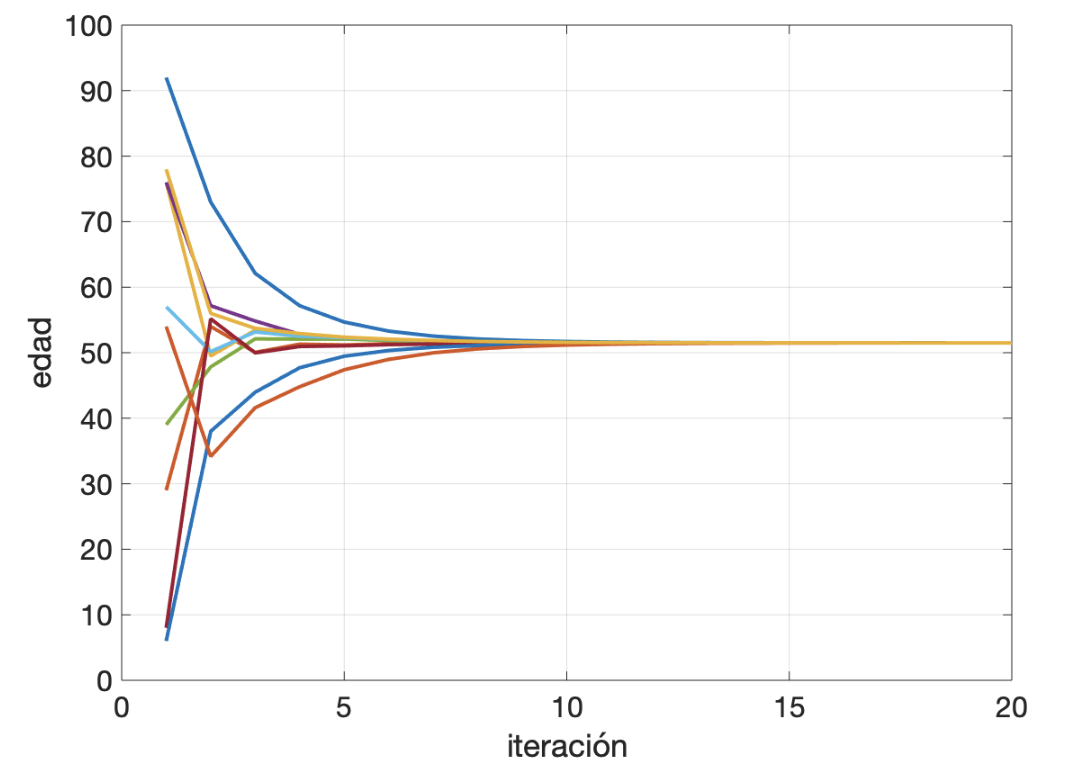
Y este proceso se repite hasta que no se producen cambios. El resultado es que cada persona tiene el valor de la edad media del grupo. Por ejemplo, en un grupo de 10 personas de edades 92, 29, 76, 76, 39, 57, 8, 6, 54 y 78. La persona 1 está conectada con la 2 y la 6. Cuando recibe sus edades (29 y 57 respectivamente), hace el cálculo del paso 2
\(92 + \frac{(29 – 92) + (57 – 92)}{6} = 92 + \frac{-63 – 35}{6} = 92 + \frac{-98}{6}= 75,6\)
Después de 20 pasos como este, todos los nodos de la red saben cuál es la media de la edad del grupo, 51,5 años, y el error (la suma de cuadrados de los residuos) es de \(6\times10^{-6}\).
Lo que vamos a hacer con este proceso es construir el mapa de riesgo de infección por SARS-CoV-2 en una localidad. Si hacemos esto mismo, pero usando el riesgo de infección en lugar de la edad, tendríamos el valor medio en todo el municipio ¿podemos hacer algo para refinarlo y obtener una medida de riesgo diferente para distintas zonas del municipio? ¿cuánta gente hace falta para que funcione? ¿qué error tendríamos respecto al riesgo real?
Generación de mapas de riesgo por consenso
El proceso es sencillo: cada persona indica su nivel de riesgo y la zona en la que reside (se emplean las secciones censales del INE). Luego, se seleccionan a los contactos con los que se desea compartir la información. Normalmente, serían personas a las que les dirías que tienes el covid-19: familiares, amistades y colegas de trabajo. Un máximo de 15 personas, por ejemplo.
Cuando se llega al valor final, cada persona ha obtenido el valor medio de riesgo en cada una de las secciones censales en las que está dividido su municipio. Los datos solo se han compartido con contactos de confianza. Y ni siquiera ellos han visto la información: es algo interno de la aplicación. A partir del segundo intercambio, la información empieza a estar agregada, por lo que ya es imposible muy difícil saber ningún otro índice de riesgo personal.
Para calcular el índice de riesgo, se emplean los mismos valores en una de las primeras aplicaciones de autodiagnóstico que aparecieron: coronamadrid, antecesora de la actual Radar COVID. En ella se seguía la misma escala que usaba el servicio de emergencias del 112 para valorar posibles pacientes. Puedes consultar el algoritmo de coronamadrid si quieres más detalles. La valoración máxima es de 120 y a partir de 30 existe la posibilidad de haberse contagiado.
Modelo de La Gomera
Para evitar en la medida de los posible la reidentificación de las personas y tener un mapa de riesgo con una resolución suficiente, se emplea la división en secciones censales que hace el INE para la isla de La Gomera.
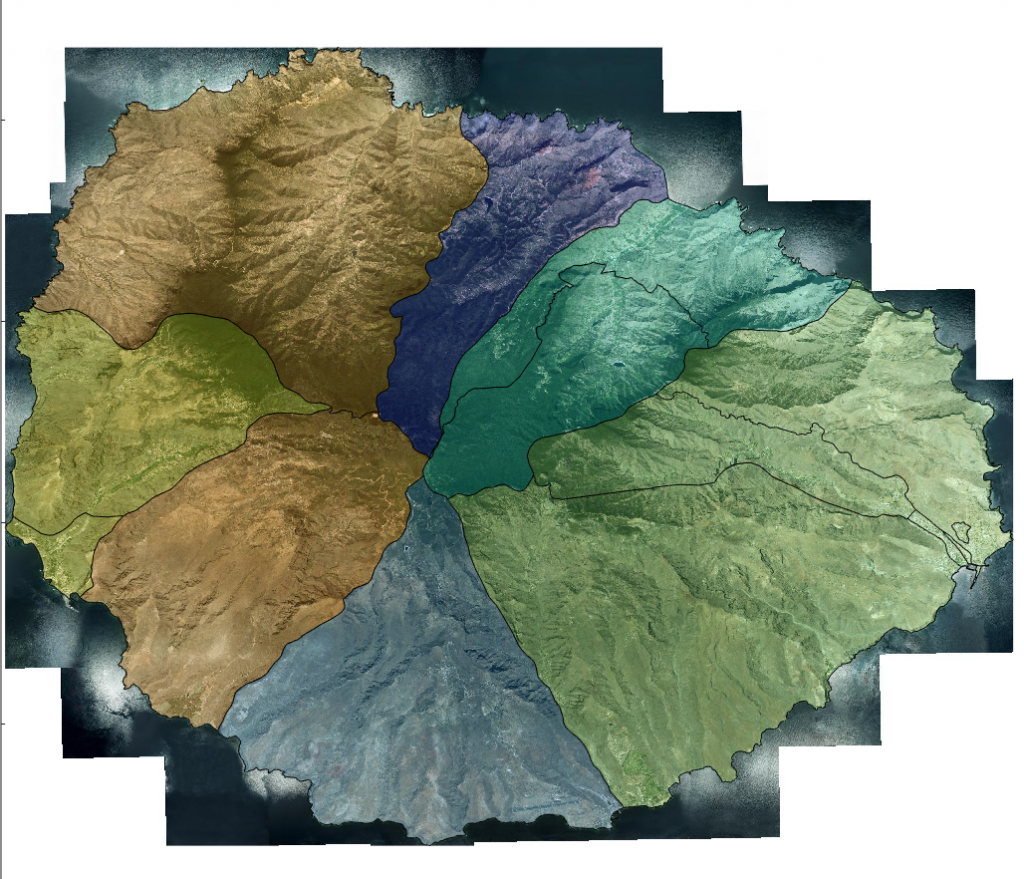
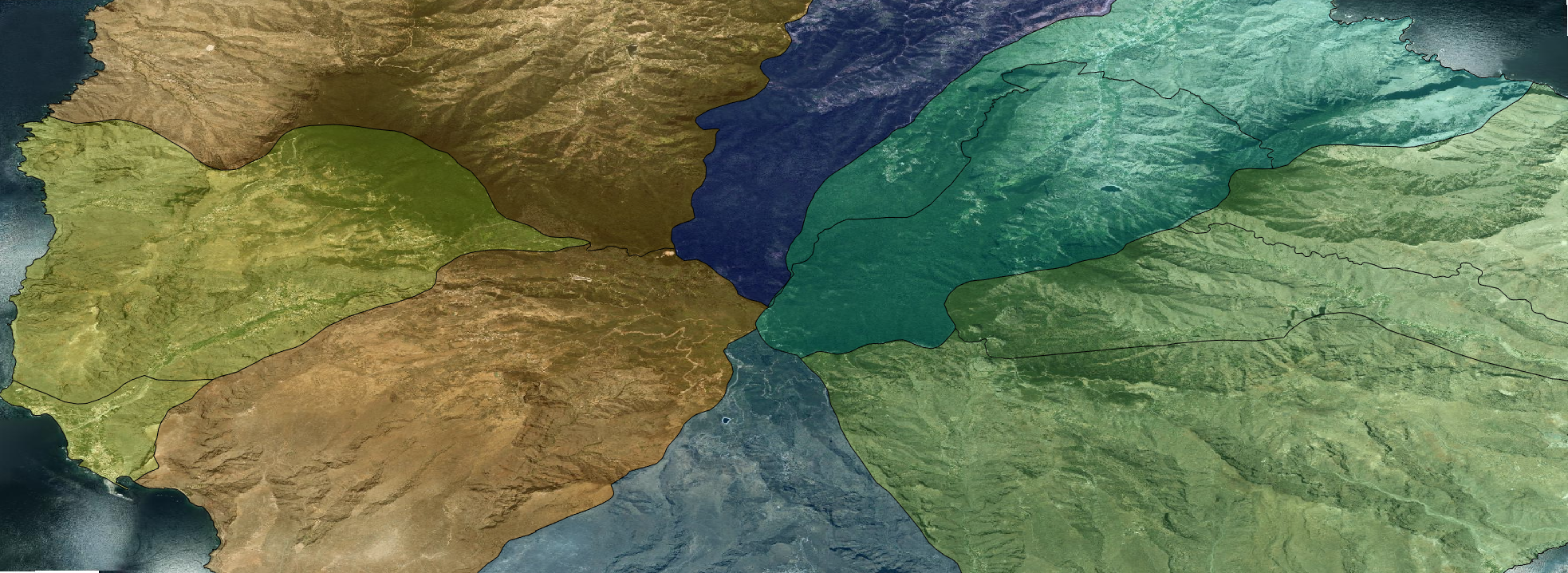
Se identifican en total 14 secciones censales para los seís municipios en los que está dividida La Gomera: Agulo, Alajeró, Hermigua, San Sebastián de la Gomera, Vallehermoso y Valle Gran Rey. El consenso se realizará entonces sobre una lista de 14 valores. Cada persona pondrá su valor de riesgo en la zona en la que reside. Ds similar a cuando vamos a un comercio y nos piden nuestro código postal. Cuando el proceso concluye, la lista contiene el valor de riesgo medio calculado para cada una de las 14 secciones censales y cualquiera podrá conocer la situación de riesgo de toda la isla.
Por ejemplo, si yo resido en Valle Gran Rey (sección 11) y mi índice de riesgo es de 45 (sobre 120), mis datos se rellenan
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 45 | 0 | 0 | 0 |
Red de contactos
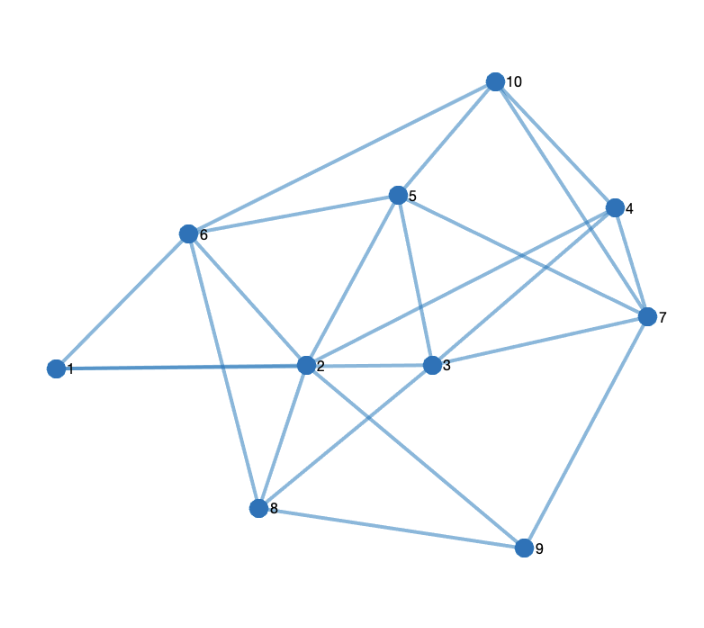
La base del modelo de consenso es la red de contactos. En múltiples estudios se ha determinado que las personas estamos unidas en redes de mundo pequeño (recuerda los seis grados de separación). Una característica adicional a estas distancias cortas es que hay algunas personas que tienen muchos más contactos que otras. Piensa, por ejemplo, en el número de seguidores en redes sociales de personas famosas. Tú puedes tener 100, 1.000 contactos, pero una famosa puede tener decenas de millones. Este tipo de distribución se conoce como ley de potencias, y es la que vamos a utilizar.
No es un capricho. Este mismo modelo lo he usado con poblaciones en la Comunidad Valenciana. En concreto, en Gandía y Albaida. Y para obtener la red usé la red formada por los seguidores en Twitter de las cuentas de los respectivos ayuntamientos. Para la Gomera, en lugar de obtener los datos de Twitter, directamente he generado una red con una distribución similar. En este caso, \(\alpha =-1,7\). Para mantener la misma proporción que en el piloto de Radar COVID, asumiré que participan 3.000 personas.
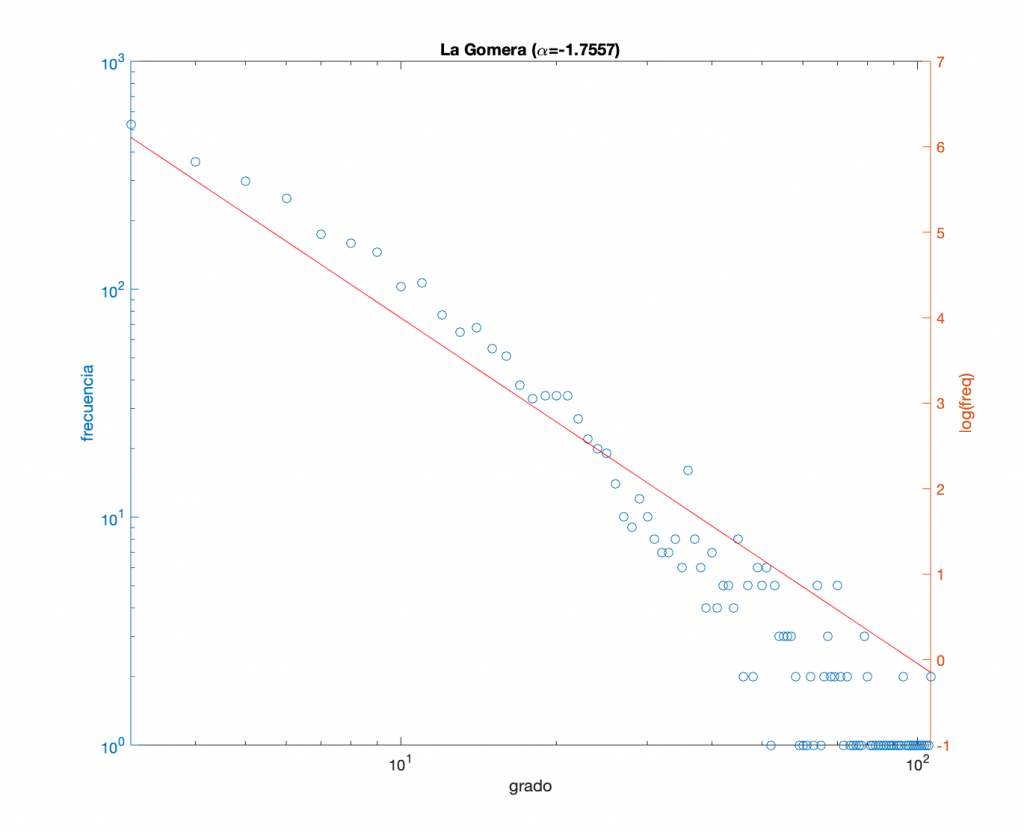
Eso genera una red de 58.000 contactos y la persona más conectada tiene 876 amistades. Para limitarlo a un máximo de 15, lo que haremos es elegir a \(9\pm 2\) contactos de cada persona. De esta forma, el número total de contactos se reduce a la mitad (unos 26.500 en el ejemplo), la persona más conectada tiene 16 y las menos conectadas 4. En la figura se puede ver cómo se reparten. Sigue una distribución de Weibull, por si a alguien le interesa saberlo.
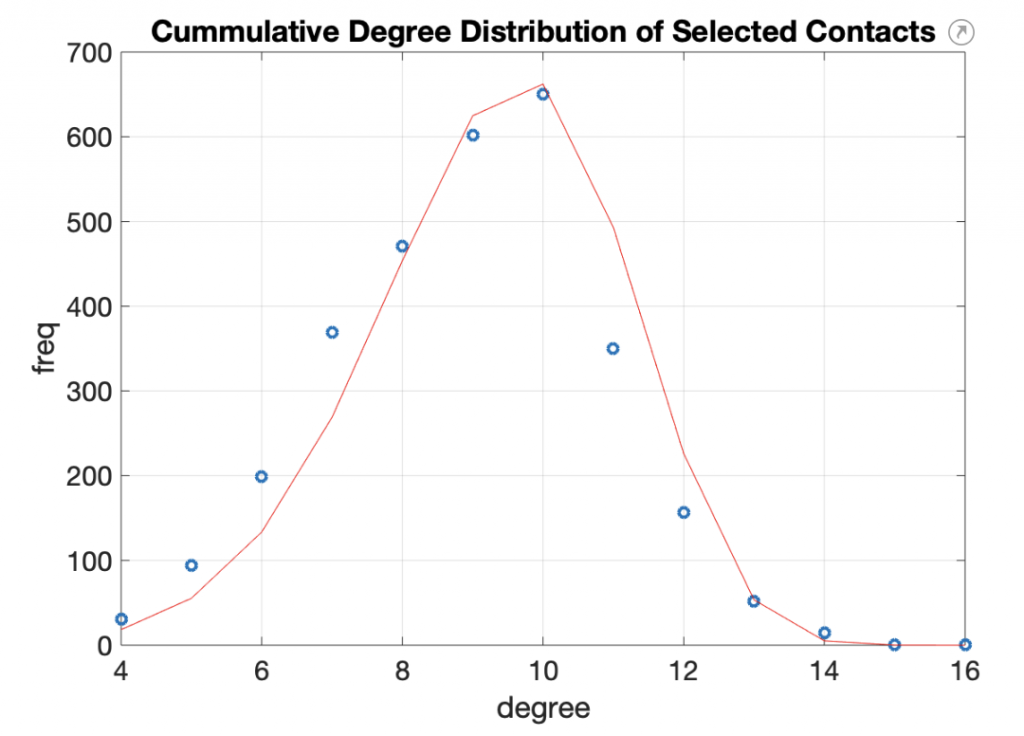
En resumen: nuestra red tiene 3.000 nodos con 10 contactos de media cada uno, variando entre 4 y 16, generados a partir de un perfil de red extraído de redes sociales.
Construcción del mapa de riesgo
Bueno, pues ya está todo listo. Tenemos la zona con la que vamos a trabajar dividida igual para todo el mundo y hemos generado una red de contactos equivalente a la que podría tener la aplicación real. Ahora veremos cómo funciona el proceso de consenso para una situación de riesgo dada. Voy a utilizar el estado en uno de los días del análisis del piloto de Radar COVID en La Gomera.
Para modelar la propagación del SARS-CoV-2 se emplea un modelo SEIR sobre una población N=21.555 (la población de La Gomera) y con 300 personas infectadas inicialmente. Las personas están distribuidas aleatoriamente por las 14 secciones censales siguiendo los datos de densidad de población que publica el INE.
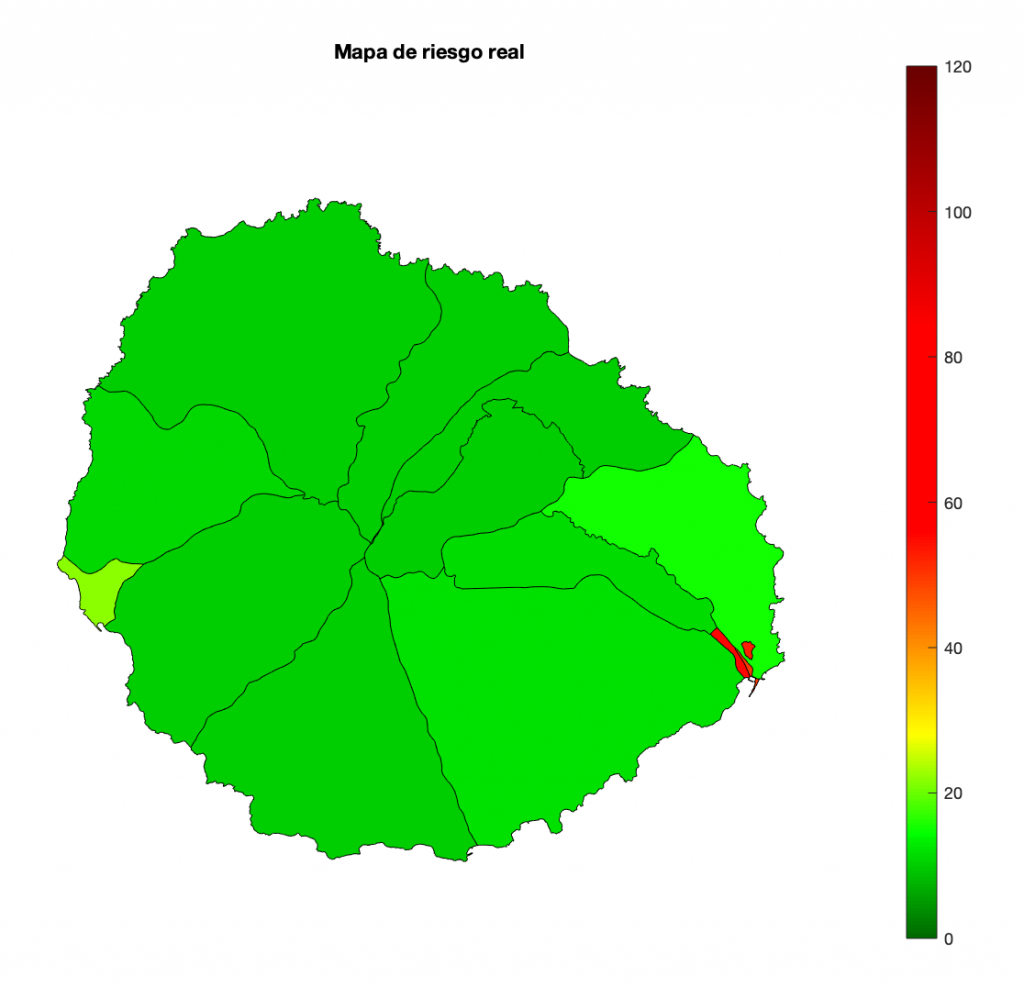
A cada persona se le asigna un índice de riesgo en función de su estado: susceptible (S), expuesta (E), infectada (I) y recuperada (R). Tras 29 días desde el inicio de la infección, San Sebastián de La Gomera tendría un índice de riesgo medio superior a 55. Las otras zonas en verde más claro estarían por encima de 20, llegando casi al límite. Este sería el mapa.
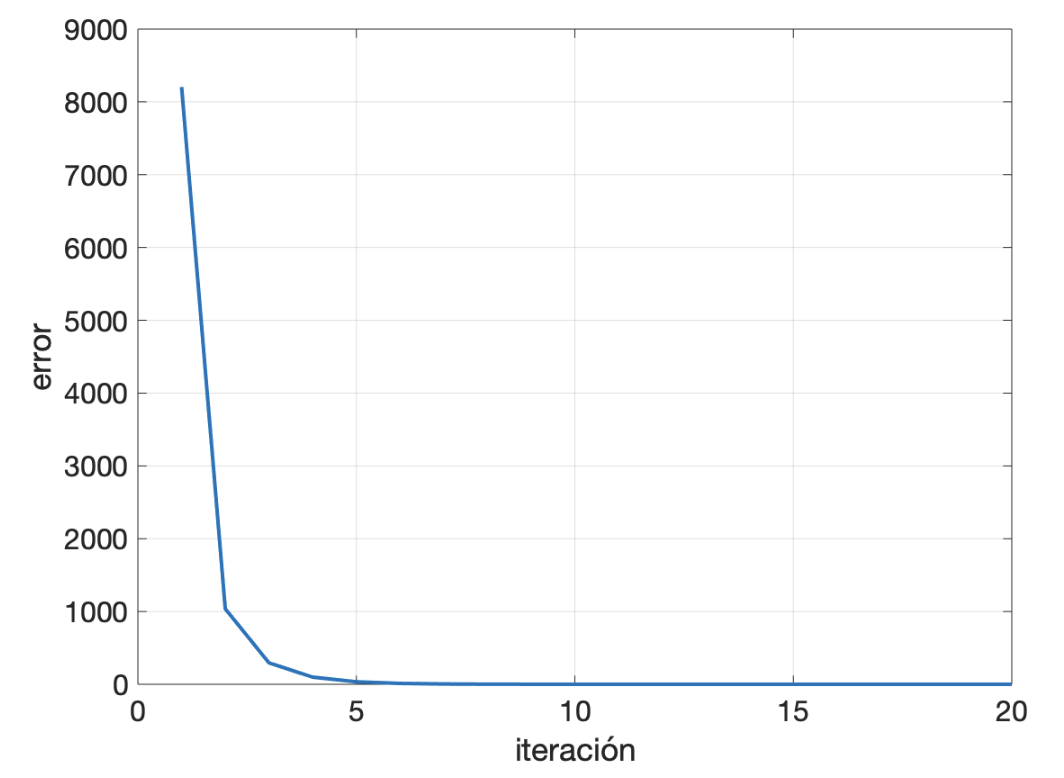
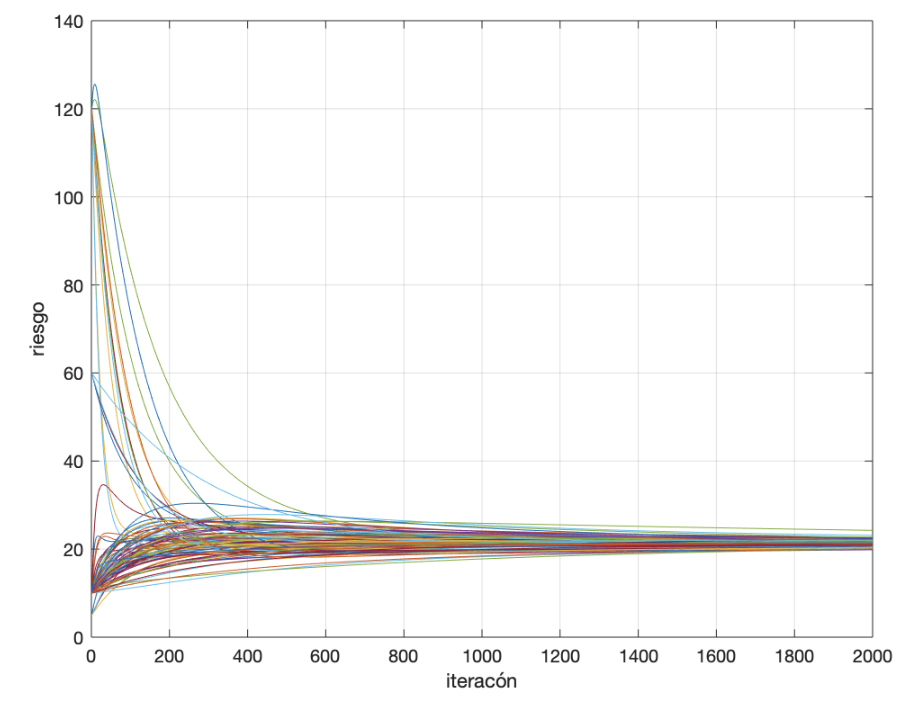
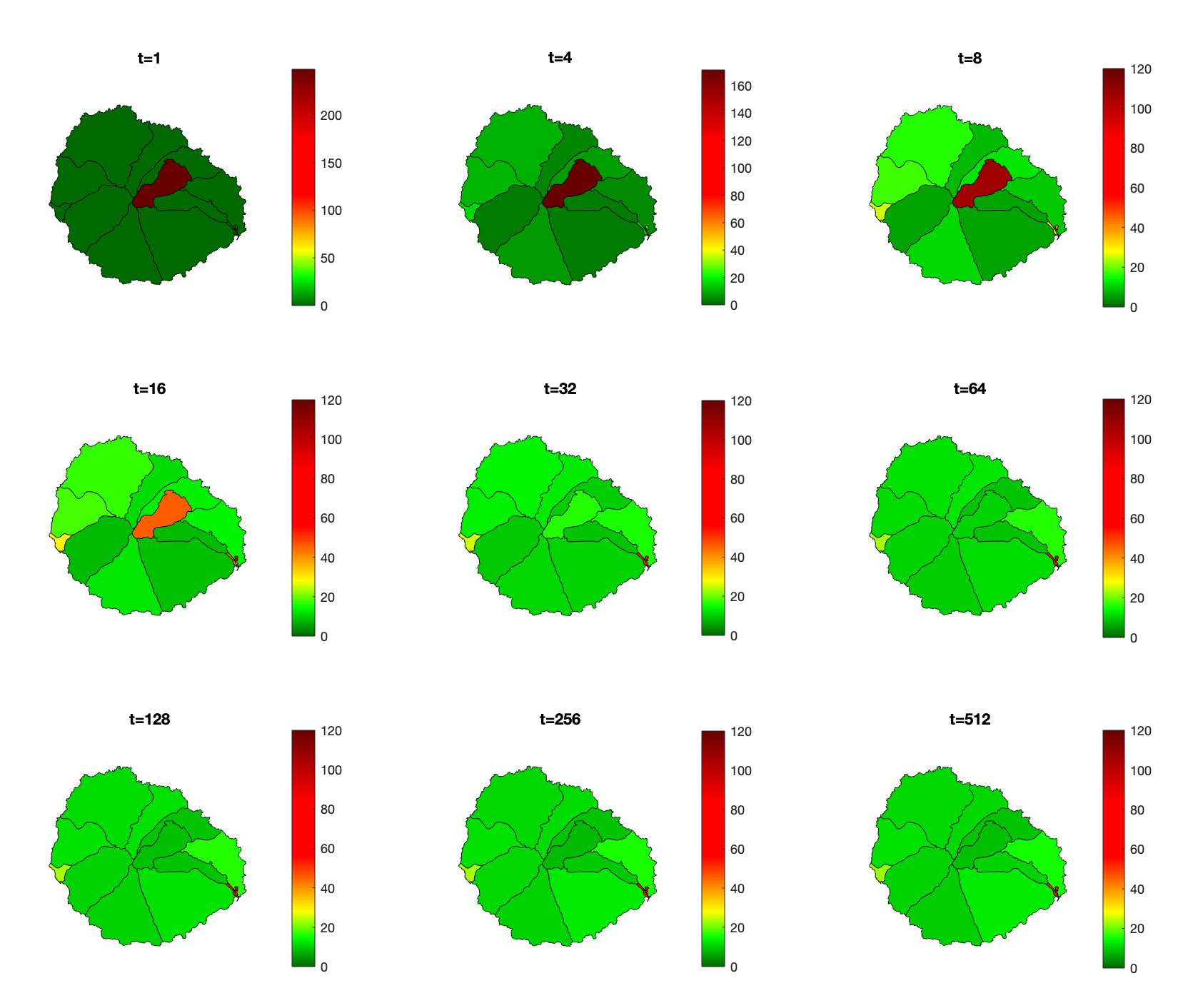
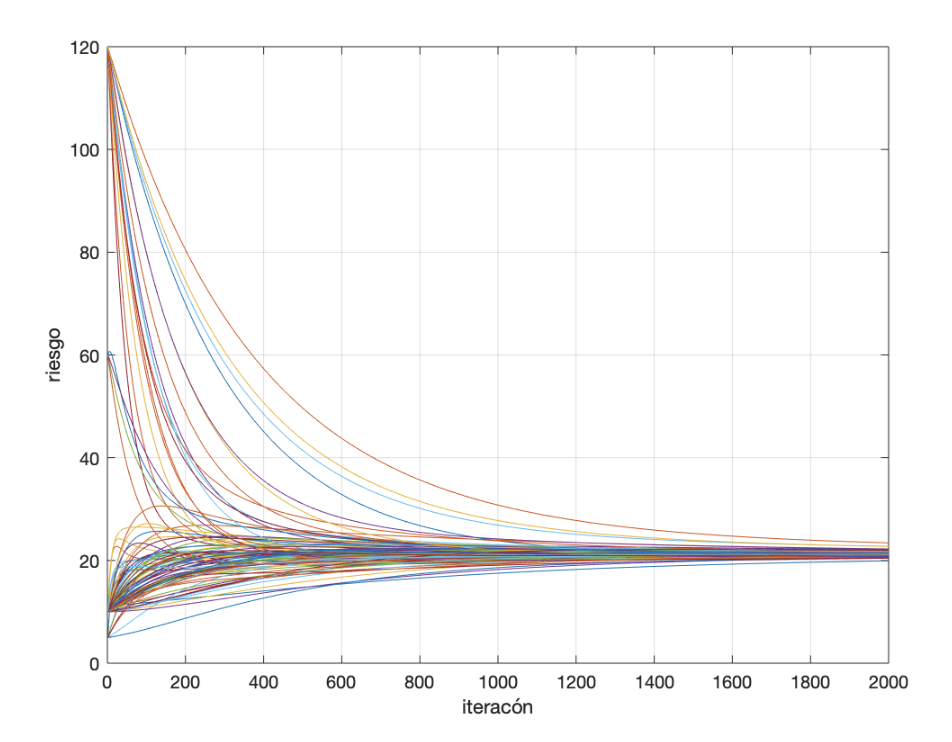
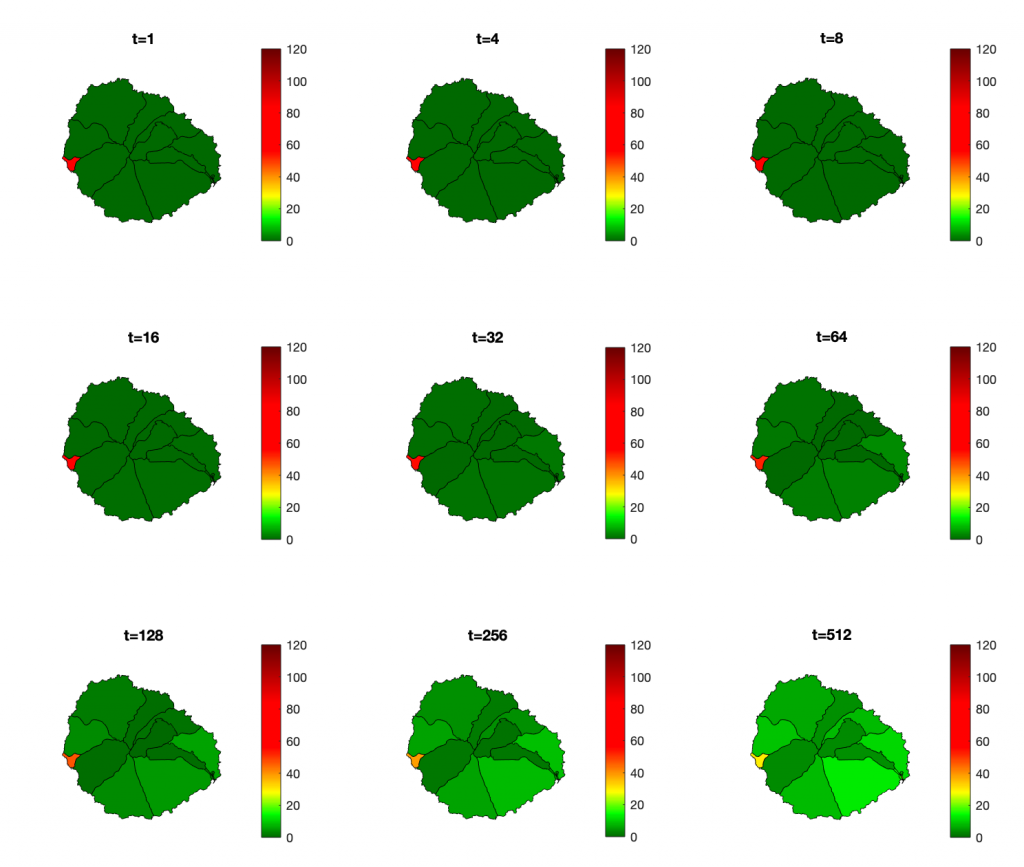
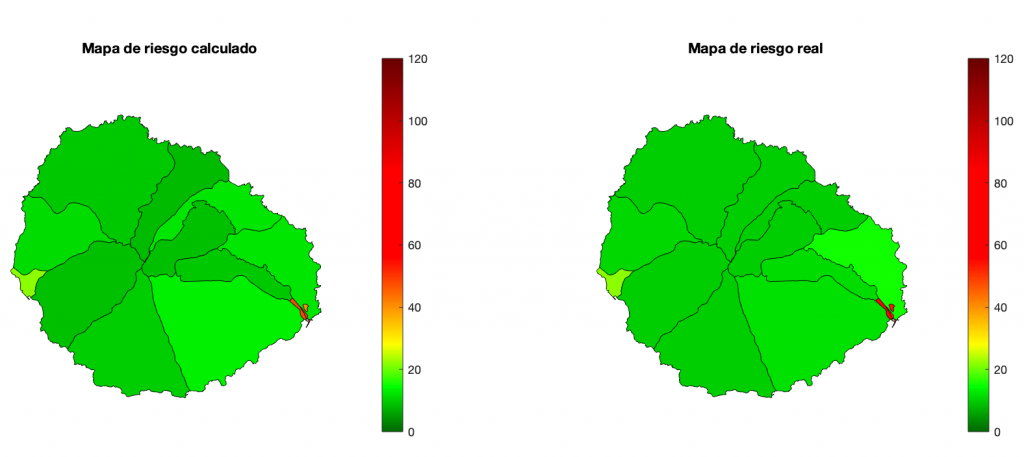
Inicialmente, y para ver que el proceso construye el mapa de riesgo exacto, ejecutaré el consenso con la red completa. En la figura de abajo está la evolución del valor de consenso, para comprobar que converge a un único valor para toda la red. También se muestra la evolución que una persona cualquiera vería del mapa de riesgo. En la primera iteración, el riesgo de toda la isla es cero, excepto en la sección en la que esa persona reside. A medida que aumentan las iteraciones, poco a poco el mapa va agregando los indices de riesgo del resto de habitantes, acercándose al definitivo. En la última figura pueden compararse el mapa final obtenido en uno de los nodos de la red con el mapa real. El error cuadrático medio es de 0,28 y el error de la suma de los residuos de 3,9.
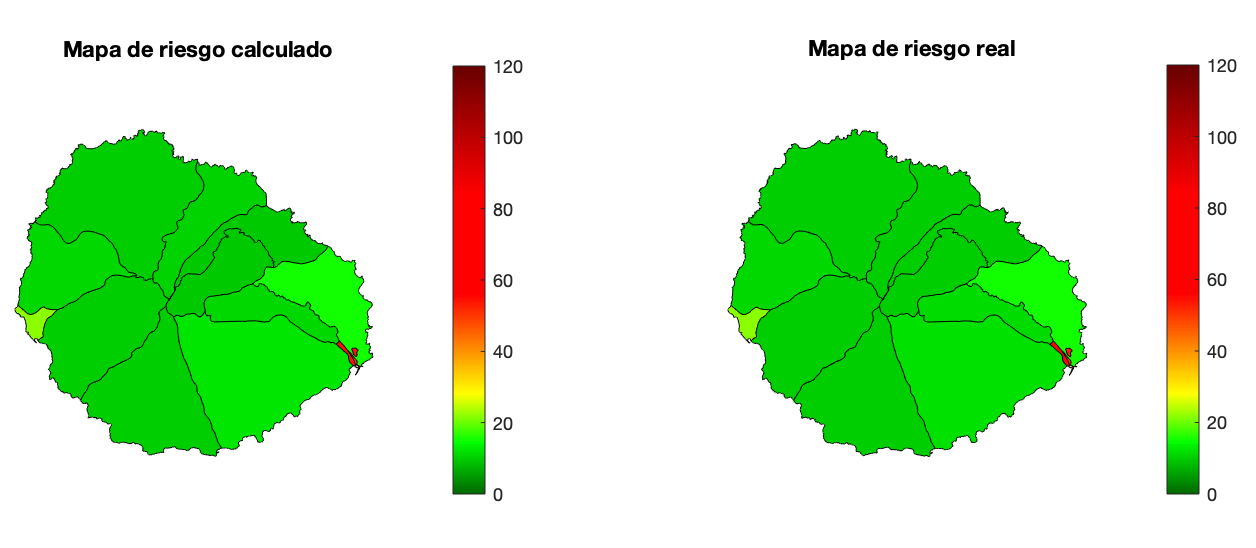
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9,9 | 10,1 | 9,9 | 9,9 | 12,2 | 11,3 | 50,3 | 55,6 | 53,1 | 15,4 | 21,8 | 9,9 | 10,9 | 10,1 |
Precisión del mapa de riesgo en función de los participantes
Esto es lo que ocurre si participa todo el mundo, pero ya sabemos que es algo imposible, así que vamos a ver qué ocurre a medida que aumentamos el número de usuarios. Empezaré con una muestra igual que la que se empleó en el piloto de Radar Covid: 3.000 participantes en la construcción del mapa de riesgo (un 15% de la población total de la isla).
En este caso, se puede apreciar a simple vista que hay una variación en los valores de riesgo que se calculan para cada área. El proceso de consenso converge más o menos a la misma velocidad y las zonas de mayor riesgo también se identifican correctamente. Sin embargo, hay variaciones más importantes en el valor de riesgo calculado, como es lógico. Ten en cuenta que solo se está utilizando el 15% de los datos. Parece una aproximación razonable.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 8,1 | 12,3 | 8,6 | 13,2 | 9,5 | 49,2 | 48,3 | 40,1 | 12,5 | 22 | 9,6 | 11,4 | 8,8 |
Pero ¿cómo de buena es esta aproximación? ¿sería útil? ¿cuántas personas hacen falta para el mapa de riesgo sea válido? Lo primero que hace falta comprobar, porque es necesario para que el consenso funcione, es que realmente se forme una red de contactos. Piensa en una red social. Funciona porque la mayoría está conectada en un solo grupo por que el fluye la información. Si fueran muchos grupos pequeños separados, no funcionarían los memes y existirían vídeos virales. Hay que intentar que la mayoría pertenezca a un gran grupo, que se llama componente gigante.
Fíjate en estas figuras. En cada una de ellas está conectado el 5 %, el 15 % o el 20% de los nodos de la red. Como ves, ya con el 20 % apenas quedan un puñado de nodos desconectados.



Pues bien ¿qué porcentaje de gente hace falta que se conecte para que aparezca este grupo? Es un resultado que se conoce desde hace tiempo: y es que el tamaño no importa. Independientemente de cuántas personas en total formen la red, la componente gigante se forma más o menos con el mismo porcentaje. Aquí tienes un ejemplo con redes de 10, 100, 1.000, 10.000 y 100.000 nodos. A partir del 20 % de los nodos, más del 80 % de la red está conectada a ese gran grupo, a la componente gigante.
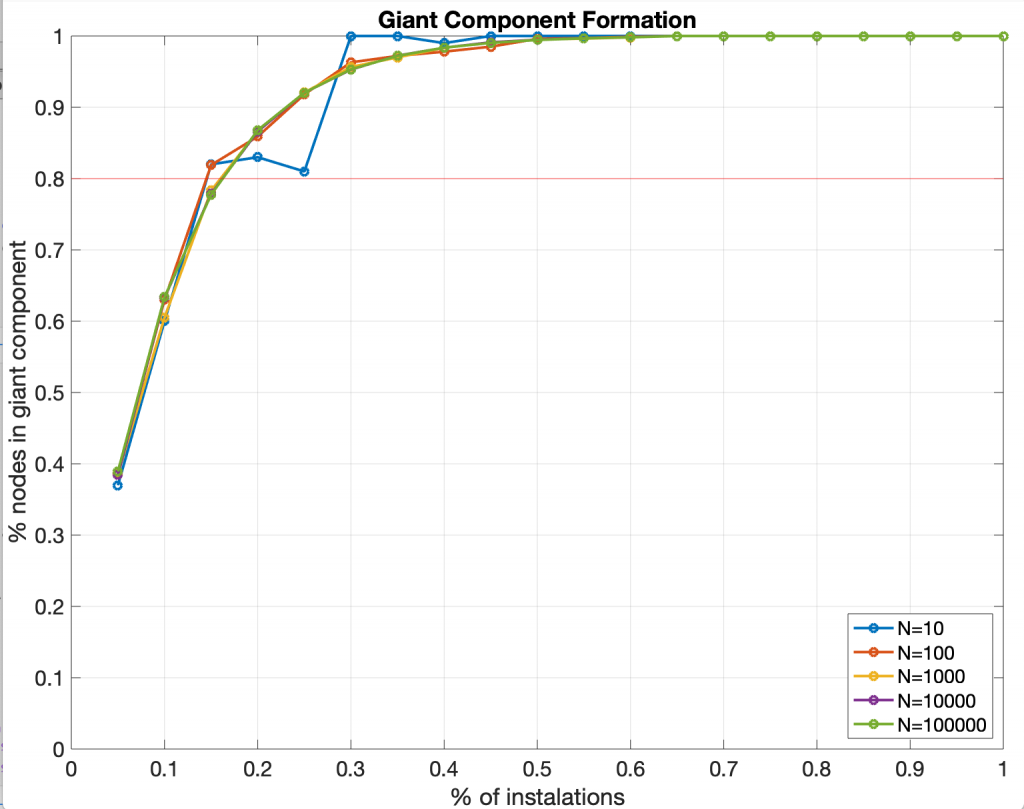
Una curiosidad. De la misma forma que la componente gigante favorece la propagación de información, ocurre lo mismo con las enfermedades. Por eso, una forma de controlarla es tratar de romper esta componente gigante en grupos pequeños. Si se llega a formar la componente gigante, es cuando tenemos transmisión comunitaria.
¿Y cuál es el error del mapa de riesgo si no participa todo el mundo? Has visto el resultado cuando lo usa un 15 % (3.000 de los 21.550 habitantes de La Gomera). Si repetimos el experimento con distintos tamaños, y para cada tamaño generamos varias redes y calculamos la media, podemos obtener la variación del error cuadrático medio a medida que aumenta el número de usuarios
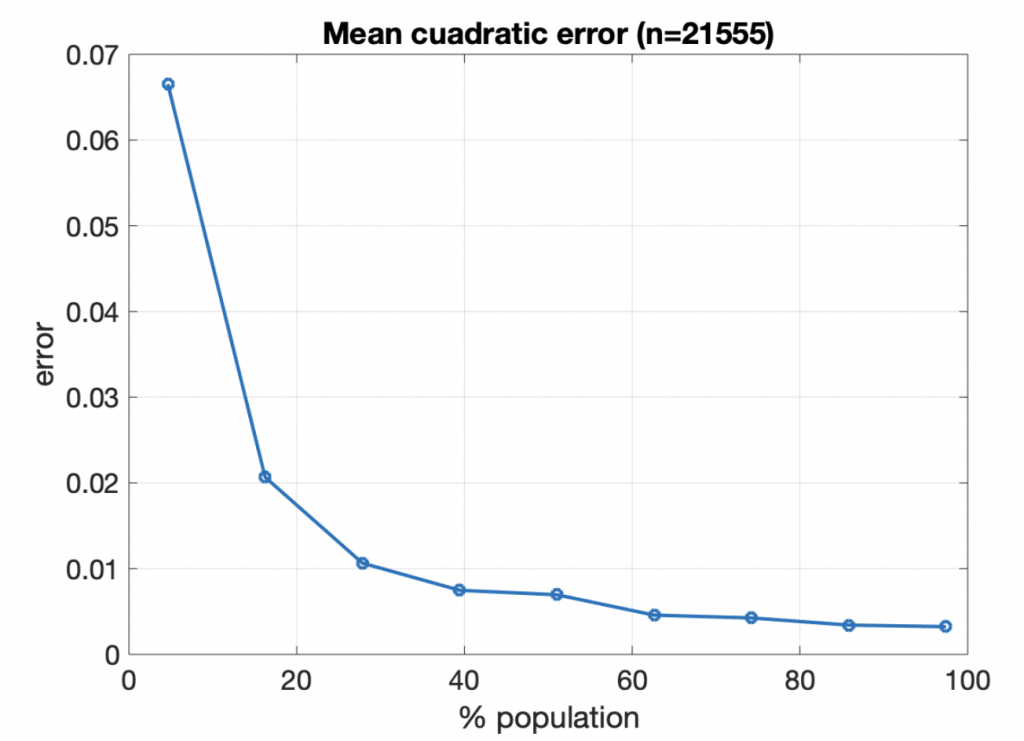
Mirando las dos gráficas, parece que alrededor del 20 % de usuarios seria suficiente para que el proceso de consenso funcione: el mapa de riesgo se construiría con los datos del 80% de participantes y el error que se cometería estaría en torno a 0,02.
Conclusión
Se puede construir una aplicación que elabore un mapa de riesgo de covid-19 de forma colaborativa usando procesos de consenso. Solo se compartiría información con contactos de confianza, minimizando los riesgos de pérdida de privacidad. Se trataría de una iniciativa de la ciudadanía para la ciudadania. Comparto mis datos con los míos para sentirnos más seguros, no con ningún gobierno, administración o empresa. Por supuesto, las administraciones locales pueden conectarse, pero serían un nodo más de la red. Tendrían acceso a la misma información que cualquiera de nosotros.
El análisis en el escenario de La Gomera, en el que se probó Radar COVID, confirma los resultados teóricos de los modelos. A partir de un 20% de los usuarios sería suficiente para que la aplicación funcionase y proporcionase datos útiles. De todas formas, sigue siendo un número demasiado grande. Todo esto sugiere que las aplicaciones no son una solución en sí mismas, si no un complemento a otras medidas que se tienen que tomar de forma conjunta.